
Hi support, I'm Jane Doe. My email is [email protected] and my order #18472 shipped to 234 Main Street. The card ending in 4242 was charged twice.
Try it
Paste any text below or pull from the 500-sample test corpus. The scrubber runs server-side using the actual published package — no LLM calls, no third parties, nothing leaves this server.
Input
Redactions
The three substitution modes
Choose per call, per category, or per label. Mix them. Save as presets.
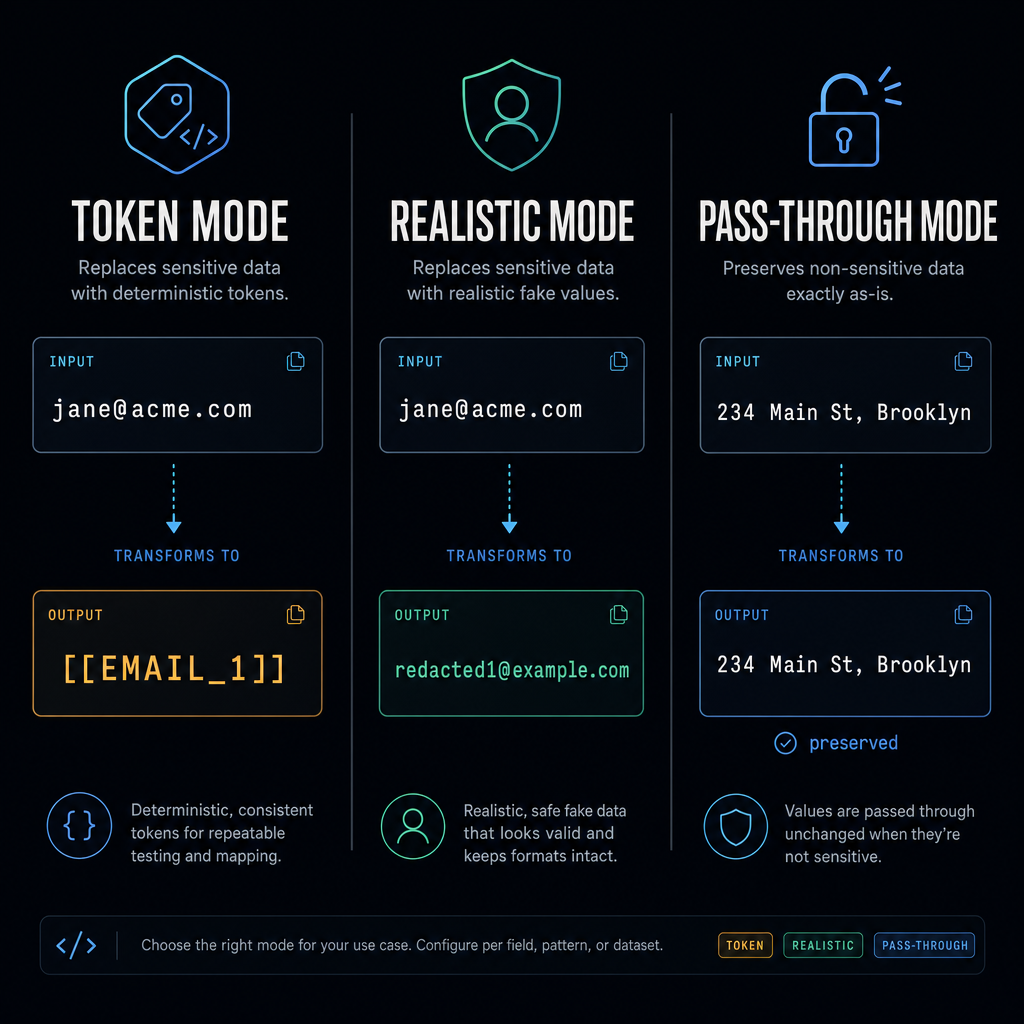
token default
my email is [email protected] ↓ my email is [[EMAIL_1]]
- Restore reliability: bulletproof
- LLM fluency: poor
- Privacy: maximum
- Use when: high-stakes data, audit trails, restore must always work
realistic
my email is [email protected] ↓ my email is [email protected]
- Restore reliability: longest-match (good)
- LLM fluency: excellent
- Privacy: high (real value never sent)
- Use when: conversational AI, content gen, anywhere fluency matters
pass-through
restaurants near 234 Main St ↓ restaurants near 234 Main St
- Restore reliability: n/a (value never changed)
- LLM fluency: excellent
- Privacy: none for that label — you opted in
- Use when: the LLM legitimately needs the value (addresses, dates, etc.)
What it catches
35+ regex patterns across 6 categories. Validators on top of the regex (Luhn, IBAN mod-97, SSN range, VIN check-digit, IPv4 octets, real calendar dates) eliminate the most common false positives. Names go through the LLM second-pass.
Loading catalog…
BYO-LLM helpers
The package never makes HTTP calls itself, but it ships helpers that build prompts and parse responses for two LLM-driven workflows. To try them live in your browser, head to the Demo tab and click Enable AI audit. This page documents the API.
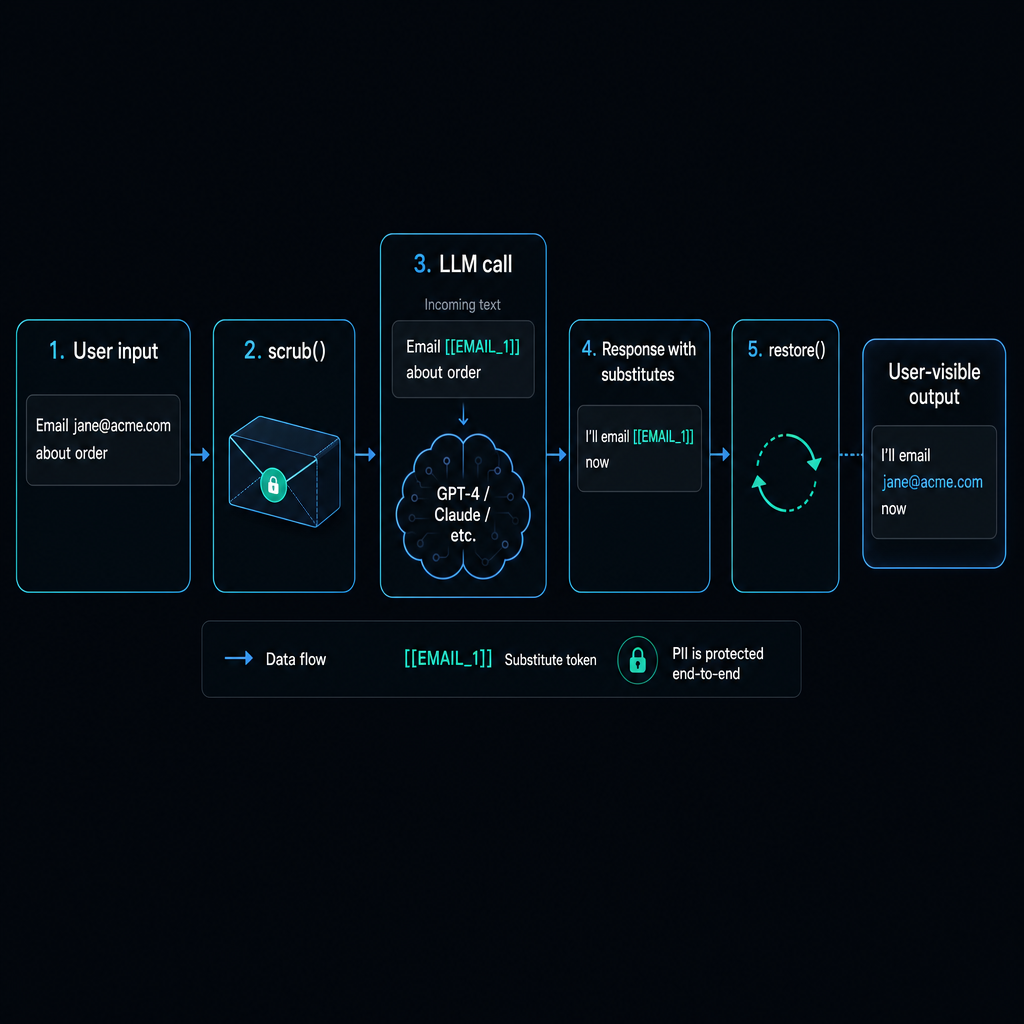
1. Audit pass — add missed PII and release false positives
The auditor reviews the regex output. It adds anything the regex missed (names,
codenames, free-form identifiers), and it releases any false positives the regex
flagged in error (LAN IPs, documented test cards, sample SSNs in code comments).
The release path has a hard server-side safety override: any label whose category
is secrets, financial, or identifiers can
never be released by the LLM — even if the model asks. This is enforced by
applyPiiAudit, not by prompt engineering.
import {
scrub, createSession, listRedactions,
buildPiiAuditPrompt, parsePiiAuditResponse, applyPiiAudit
} from 'piivacy';
const session = createSession();
// Pass 1: regex
await scrub(text, session);
const inv = listRedactions(session);
// Pass 2: ask any chat LLM to audit
const { system, user } = buildPiiAuditPrompt(text, inv);
const reply = await yourLlm.chat.completions.create({
messages: [
{ role: 'system', content: system },
{ role: 'user', content: user }
]
});
// Parse + apply with safety override
const audit = parsePiiAuditResponse(reply.choices[0].message.content);
const result = applyPiiAudit(session, audit, {
minConfidence: 0.6, // floor for additions
releaseMinConfidence: 0.85 // floor for false-positive releases (stricter)
});
// result === { added, removed, blocked, blockedItems }
// Pass 3: re-scrub with the audit applied
const { text: finalText } = await scrub(text, session);
Try this live on the Demo tab. The audit runs entirely in your
browser via Qwen2.5-1.5B-Instruct (WebLLM), cached locally in IndexedDB
after first download.
2. Intent-driven mode picking
Some queries legitimately need certain PII to be readable by the LLM (addresses for local search, dates for scheduling). Instead of hard-coding which categories to keep, let an LLM read the user's query and decide which categories should be redacted, preserved as-is, or replaced with realistic synthetic values.
import {
scrub, createSession,
buildScrubIntentPrompt, parseScrubIntentResponse, applyScrubIntent
} from 'piivacy';
const { system, user } = buildScrubIntentPrompt(userQuery);
const reply = await yourLlm.chat.completions.create({
messages: [{ role: 'system', content: system }, { role: 'user', content: user }]
});
const { decisions } = parseScrubIntentResponse(reply.choices[0].message.content);
const opts = applyScrubIntent(decisions, { defaultMode: 'token' });
// opts.modes === { location: 'pass-through', contact: 'token', ... }
const session = createSession();
const { text } = await scrub(userQuery, session, opts);
Hard safety in applyScrubIntent: secrets,
financial, and identifiers categories cannot be set to
pass-through. The override fires before any scrub call sees the opts.
The 267,072-name fake-name table
Realistic-mode NAME redaction uses a static table shipped with the package: 104,819 first names from the US Social Security Administration and 162,253 surnames from the US Census 2010 Surnames file — both public domain.
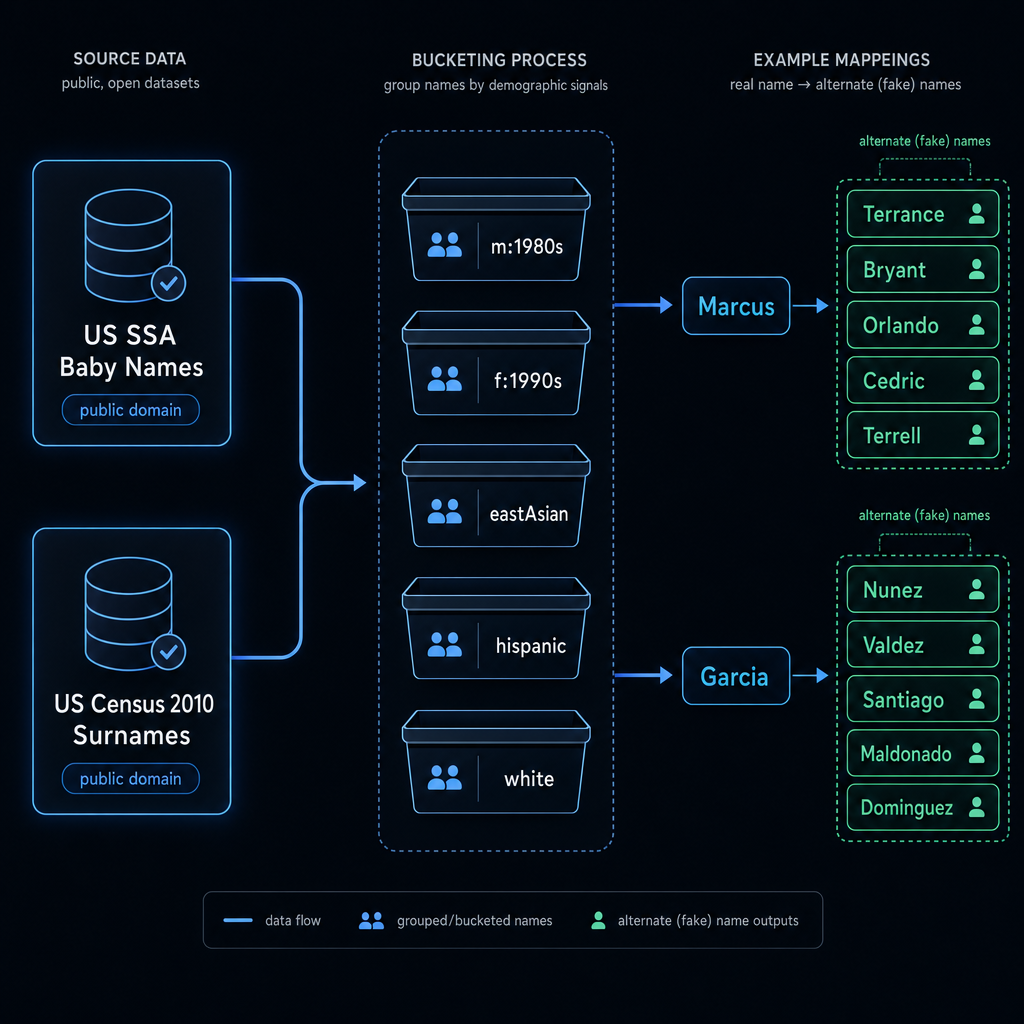
How alternates are picked
- Bucket every name by demographics.
First names →
(sex, decade-of-peak-popularity)~30 buckets. Surnames → dominant Census ethnic distribution (white,eastAsian,southAsian,hispanic,black,native,mixed). - Pick alternates from the bucket's top 1000. Each name's 5 alternates come from a hash-determined offset into the same bucket's top-frequency names, with a Levenshtein-distance filter to exclude spelling variants.
Examples from the shipped table
| Real name | Bucket | Alternates |
|---|---|---|
| Marcus | m:1980s | Terrance, Bryant, Orlando, Cedric, Terrell |
| Sarah | f:1980s | Amber, Danielle, Brittany, Tiffany, Crystal |
| Mervyn | m:1930s | Ned, Delmar, Dudley, Arlen, Huey |
| Liam | m:2020s | Waylon, Griffin, Ellis, Rowan, Alonzo |
| Garcia | hispanic | Nunez, Valdez, Santiago, Maldonado, Dominguez |
| Nguyen | eastAsian | Li, Wong, Le, Wang, Park |
| Patel | southAsian | Sharma, Chu, Ma, Chin, Kumar |
Tried but didn't ship: embedding nearest-neighbor
First build attempt used OpenAI text-embedding-3-small for nearest-neighbor
within bucket. Result was poor — text-embedding models cluster name tokens by orthographic
stem, so Marcus mapped to "Marquis", "Marquise", "Marrio" — spelling variants of itself,
exactly the failure mode we wanted to avoid. Frequency-rank-with-hash-offset within the
demographic bucket produces the recognizable common alternates you actually want.
Regenerate or extend the table
The build script is in the repo at
scripts/build-names.mjs.
It downloads SSA + Census data, buckets, picks alternates, writes data/names.json:
git clone https://github.com/callieschneider/piivacy
cd piivacy
node scripts/build-names.mjs # full pipeline
node scripts/build-names.mjs --pool-size=500 # smaller pool
To add non-Latin scripts (Hangul, CJK, Arabic, Devanagari): the format is just
{ firstNames: { lowername: { bucket, alternates: [...] } } }. Merge in any
data source you trust. PRs welcome.
How to use it
Quick start
import { scrub, restore, createSession } from 'piivacy';
const session = createSession();
// Before sending to the LLM
const { text } = await scrub(userInput, session);
// Send to your LLM
const reply = await openai.chat.completions.create({
model: 'gpt-4o-mini',
messages: [{ role: 'user', content: text }]
});
// Put the PII back
const restored = restore(reply.choices[0].message.content, session);Per-category modes
await scrub(text, session, {
defaultMode: 'token',
modes: {
contact: 'realistic', // emails, phones → fakes
location: 'pass-through', // addresses preserved
secrets: 'token' // API keys → [[OPENAI_KEY_1]]
}
});Per-label overrides
await scrub(text, session, {
defaultMode: 'token',
modes: { contact: 'realistic' },
labels: {
EMAIL: 'realistic', // explicit wins
DOB: 'pass-through', // we want to discuss age
ZIP_US: 'token' // override location-category default
}
});Built-in presets
import { presets } from 'piivacy';
await scrub(text, session, presets.maximumRedaction);
// → tokens for everything
await scrub(text, session, presets.naturalConversation);
// → contact + location realistic; secrets/financial/identifiers token
await scrub(text, session, presets.localSearch);
// → location pass-through; everything else tokenized
await scrub(text, session, presets.testFriendly);
// → realistic where possible; token for danger categoriesAdd your own pattern
import { registerPattern } from 'piivacy';
registerPattern({
label: 'INTERNAL_TICKET',
regex: /\bTICKET-\d{6}\b/g, // /g flag REQUIRED
category: 'custom',
priority: 25, // slots between defaults
validate: (v) => Number(v.slice(7)) > 100000,
fake: (_value, { counter }) =>
`TICKET-${(counter + 1000).toString().padStart(6, '0')}`,
description: 'Internal Jira-style ticket'
});Inspect what was redacted
import { listRedactions } from 'piivacy';
await scrub('email [email protected] phone (415) 555-0142', session);
console.log(listRedactions(session));
// [
// { kind: 'token', identifier: '[[EMAIL_1]]', label: 'EMAIL',
// value: '[email protected]', count: 1, firstSeenAt: ..., lastSeenAt: ... },
// { kind: 'token', identifier: '[[PHONE_US_1]]', label: 'PHONE_US',
// value: '(415) 555-0142', count: 1, ... }
// ]Useful for audit trails, downstream feature calls, and debugging.
How this was built
The whole package — source, tests, README, names data — was built in a single coding session with an AI agent (Claude Opus, in Cursor). Design the API, hand pieces off to be coded, review, run tests, fix, ship.
Stats
- ~80 KB of source code in 13 files
- 35+ default PII patterns across 6 categories
- 218 passing tests in 18 test files
- Zero runtime dependencies. Zero devDependencies. Plain ESM,
node:test. - ~23 MB shipped names table covering 267,072 names
- 2.1 MB compressed npm tarball
What it catches / What it misses
Catches reliably
- Emails, US + E.164 phones
- US/UK/Canadian addresses + postcodes
- SSN (range-validated)
- Credit cards (Luhn-validated)
- IBANs (mod-97 validated)
- VINs (check-digit validated)
- JWTs and 25+ provider API keys
- IPv4/IPv6 addresses
- Dates of birth (calendar-validated)
- MAC addresses
- BTC and ETH wallet addresses
- Lat/long coordinates
- PEM/SSH/PGP private key blocks
Misses (use the LLM second-pass)
- Names ("Jane Doe", "Dr. Smith")
- Companies, projects, codenames
- Free-form sensitive context ("my divorce", "the layoff")
- Unicode email local-parts
- Non-Latin-script identifiers
- PII embedded in unstructured prose with no formatting
Defense in depth, not a magic shield. Regex is the fast filter; LLM check is the accurate filter; your security review is the human in the loop.
Disclaimer
This package reduces the surface area for accidentally pasting PII into an LLM. It does not:
- Guarantee zero leakage (regex misses things; LLMs may infer)
- Replace your security review process
- Replace data-handling agreements with your LLM provider
- Provide cryptographic guarantees
- Constitute compliance with GDPR / CCPA / HIPAA / etc.
If you're handling regulated data, consult a security professional. If you're trying to stop yourself from accidentally pasting your customer's SSN into Claude, this is the right tool.
License
MIT. Use it, fork it, extend it. Both the package and this demo site are open source.
Built with public-domain data
- US Social Security Administration Baby Names — public domain
- US Census 2010 Surnames — public domain
For AI agents
If you're an AI agent (Cursor, Claude Code, Continue, Cline, Aider, Devin) — or you're
instructing one to integrate PIIvacy into your project — the agents page has copy-paste
recipes for every major coding agent. Plus a structured manifest at
/.well-known/agents.json and a markdown spec at /agents.md.
Get in touch
Questions, bug reports, partnership ideas, or just want to chat? The form below sends straight to the maintainer's inbox via Resend. No email address exposed.